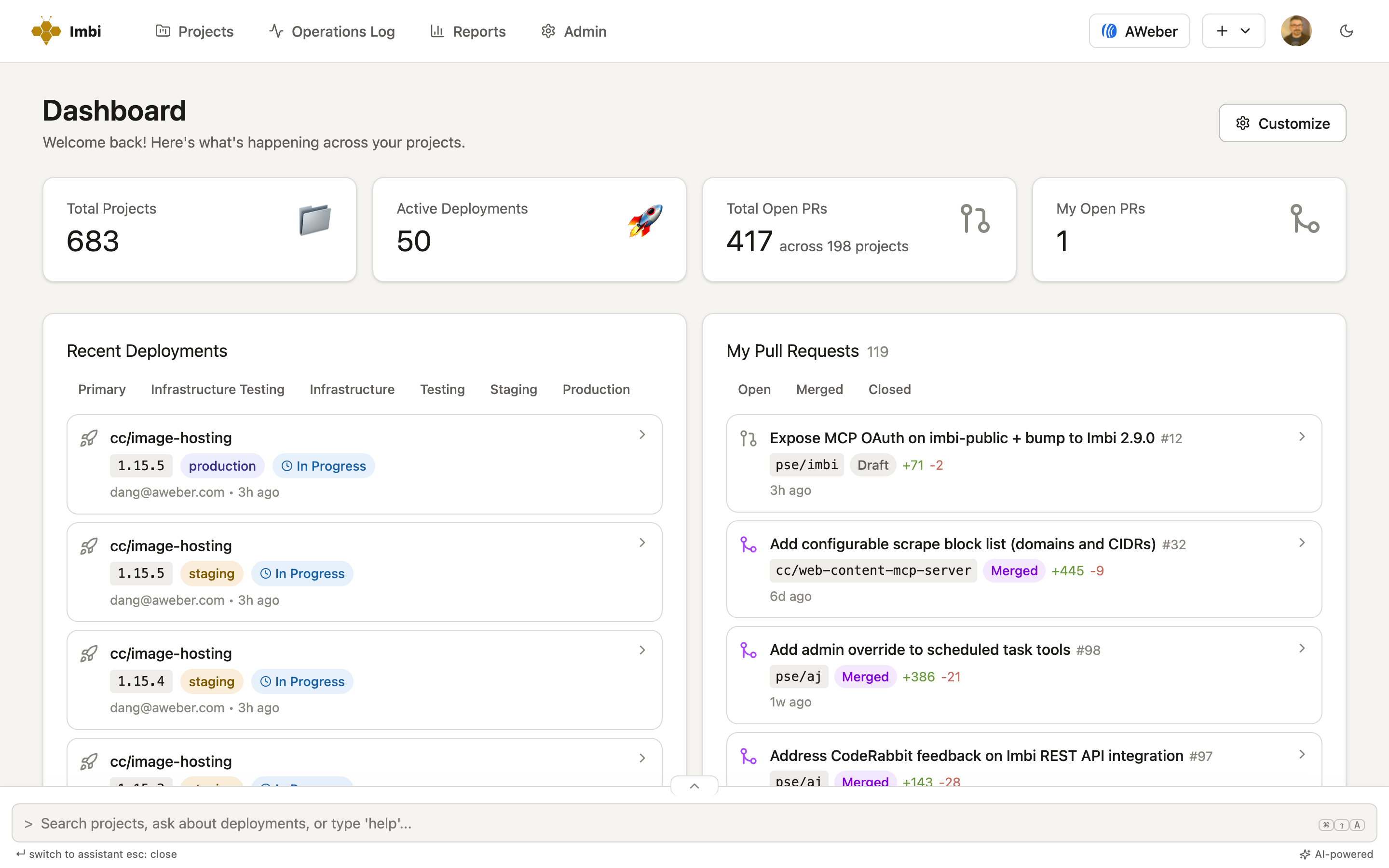
Imbi gives engineering leaders one place to see every service their organization runs, how healthy each one is, and a way to move the entire fleet forward at once — instead of a ten-tab scavenger hunt and a wiki nobody trusts.
Discovery gets harder every quarter. Standards drift faster than they can roll out. Health becomes a feeling, not a number. And the AI tools your teams just adopted can't answer a single question that crosses a repo.
GitHub, the on-call tool, dashboards, a spreadsheet, a Slack thread, and "ask the person who wrote it." Nobody can say which services depend on a database without a week of digging.
You publish a new standard. Adoption takes a year. A newer standard lands before the last one finished rolling out. "Are we compliant?" turns into an archaeology project.
Teams can't prioritize the worst offenders because there's no scoreboard — just a feeling and a dashboard nobody opens. You can't manage what you can't rank.
Coding assistants are productive inside one repo and lost across them. Nothing describes your services as a whole, so they guess about your infrastructure — or give up at the boundary.
Services, the teams that own them, what they depend on, and where they're deployed — all connected, always current. Answer "what breaks if this goes down?" before the incident, not during it.
Upstream and downstream in one view — the dependencies a service relies on, and everything that relies on it.
Imbi keeps the map in sync with the tools your teams already use, so it never goes stale the way a wiki does.
One click shows everything an outage would touch, which teams own each piece, and who's on call.
Every service knows its team, its on-call rotation, and the environments it's deployed to — no side spreadsheet.
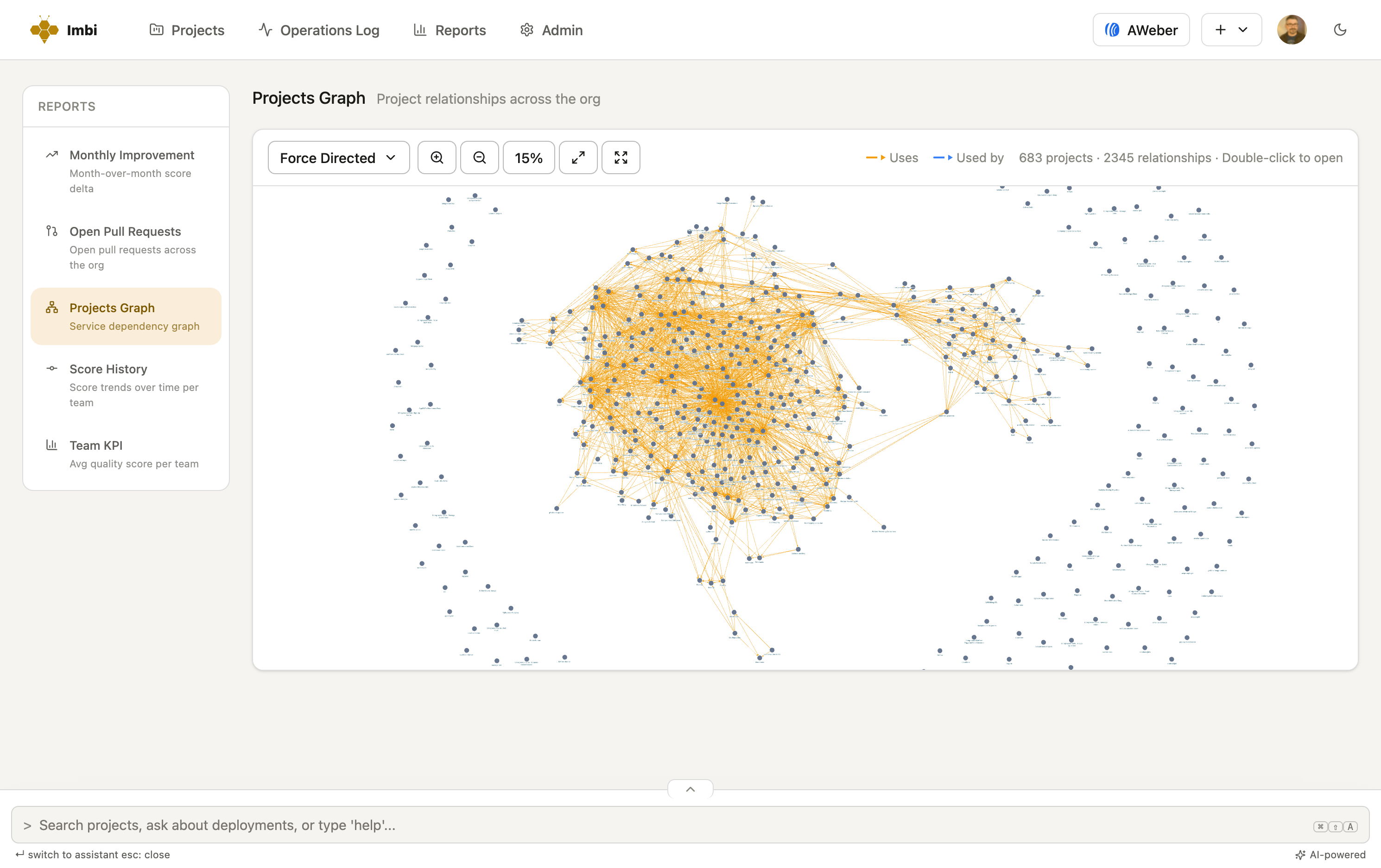
The real thing — 683 services and 2,345 relationships in one production deployment.
An API, a scheduled job, a frontend, and a shared library don't need the same checklist. Imbi lets your platform team define the fields that matter for each — required where it counts, kept honest automatically, and visible to everyone.
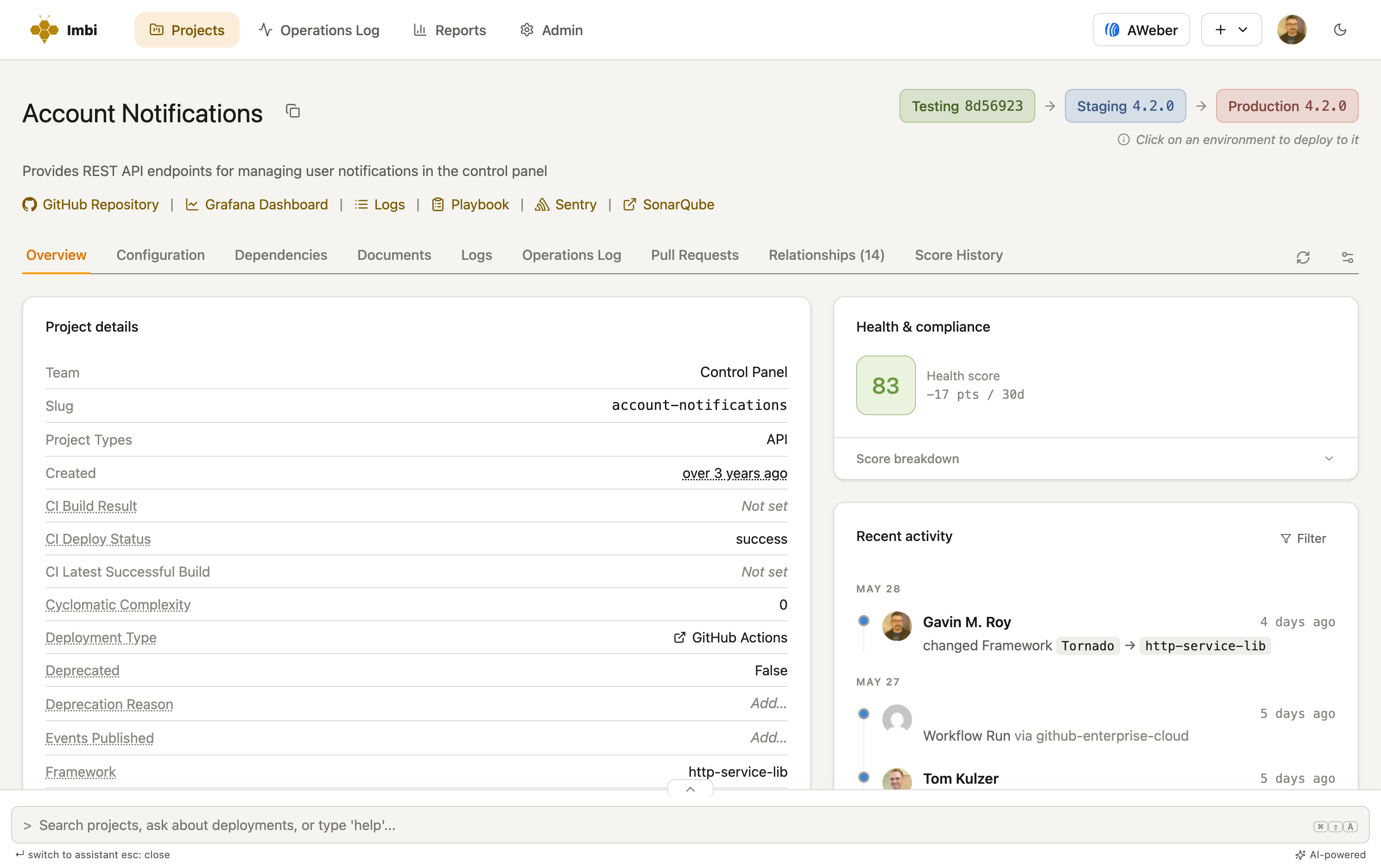
Imbi turns your standards into a number from 0–100 and puts it everywhere — on each service, rolled up per team, and across the whole org. Governance stops being a meeting and becomes a dashboard the worst offenders can't hide from.
Is it on a supported runtime? Is coverage where it should be? Every standard you set can count toward the score — and the ones that matter more count more.
Incidents, failed deploys, and quality regressions pull a score down as they happen — and it recovers when things are fixed.
A company-wide rule ("all services on a current runtime") and a team rule ("payments needs 90% coverage") can run side by side.
Every change is kept, so you can roll up by team, by org, or over any window — and answer "how is engineering doing?" with a number.
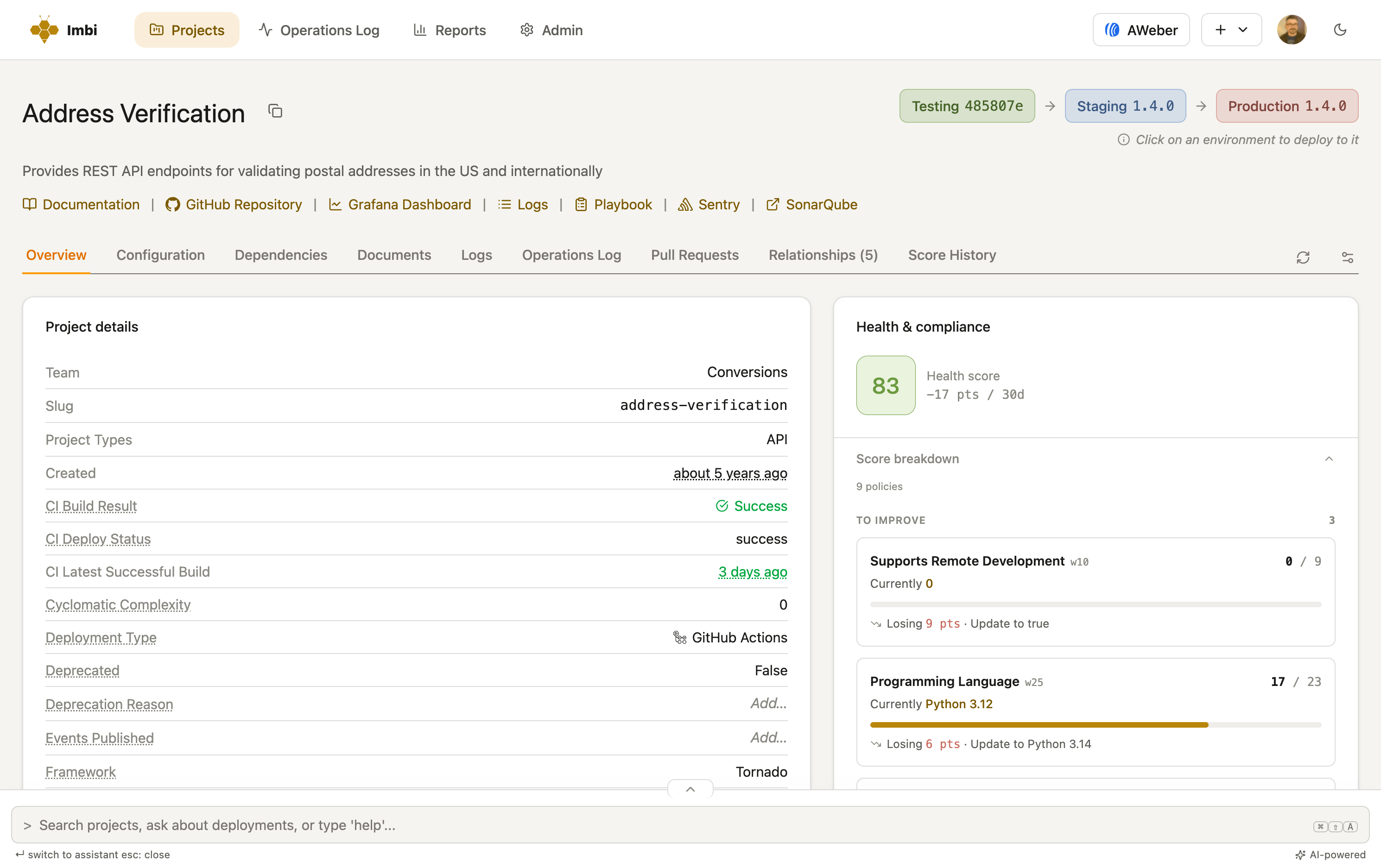
Every score is explainable: which standards a service is missing, how many points each one costs, and what to change.
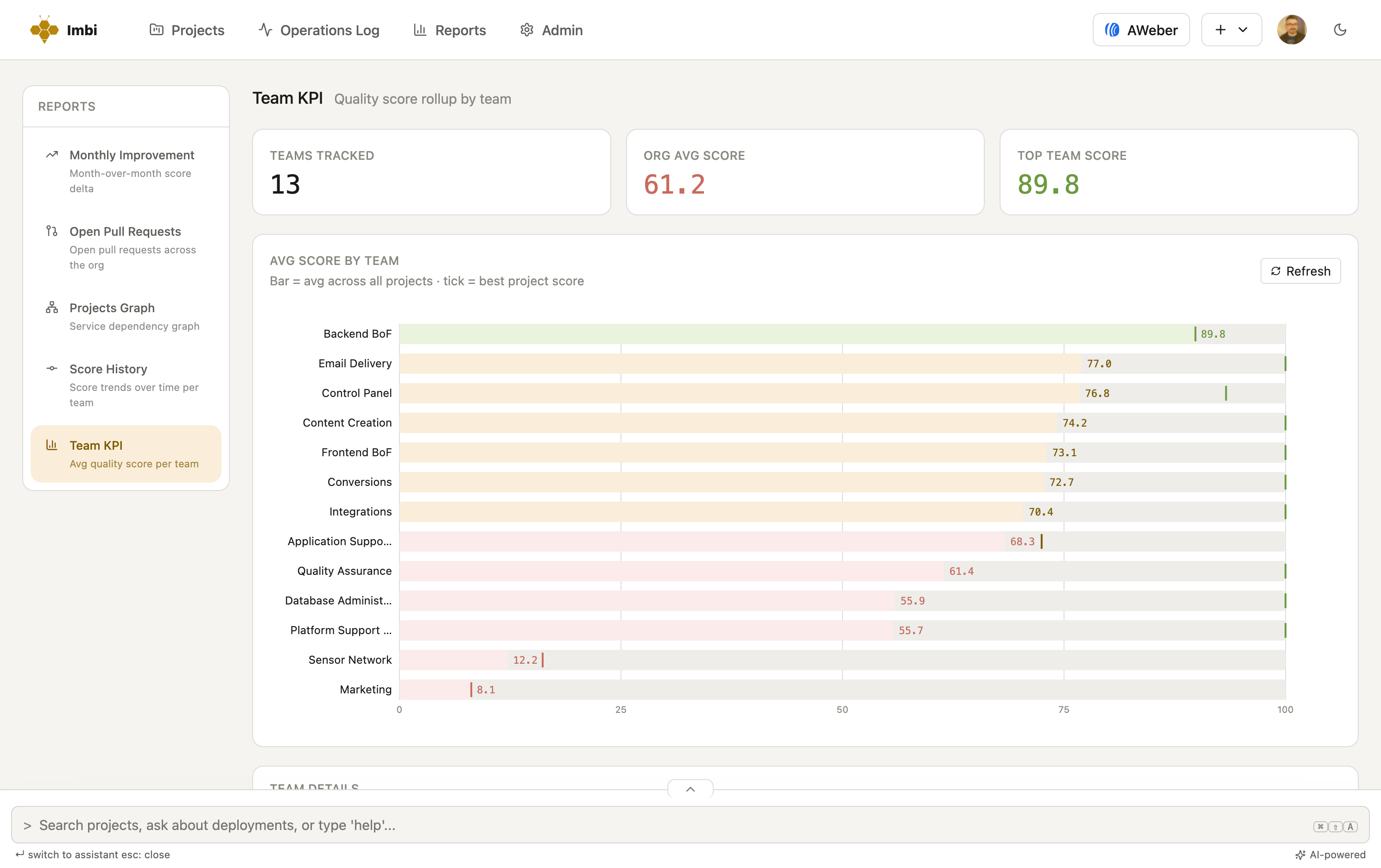
Rolled up per team, so every group can see exactly where it stands.
Imbi turns each service's pipeline into something you can actually drive. Promote a build from testing to staging to production, ship it with one click, and roll back just as fast — all wired tightly to GitHub, GitHub Enterprise, and GitHub Enterprise Cloud.
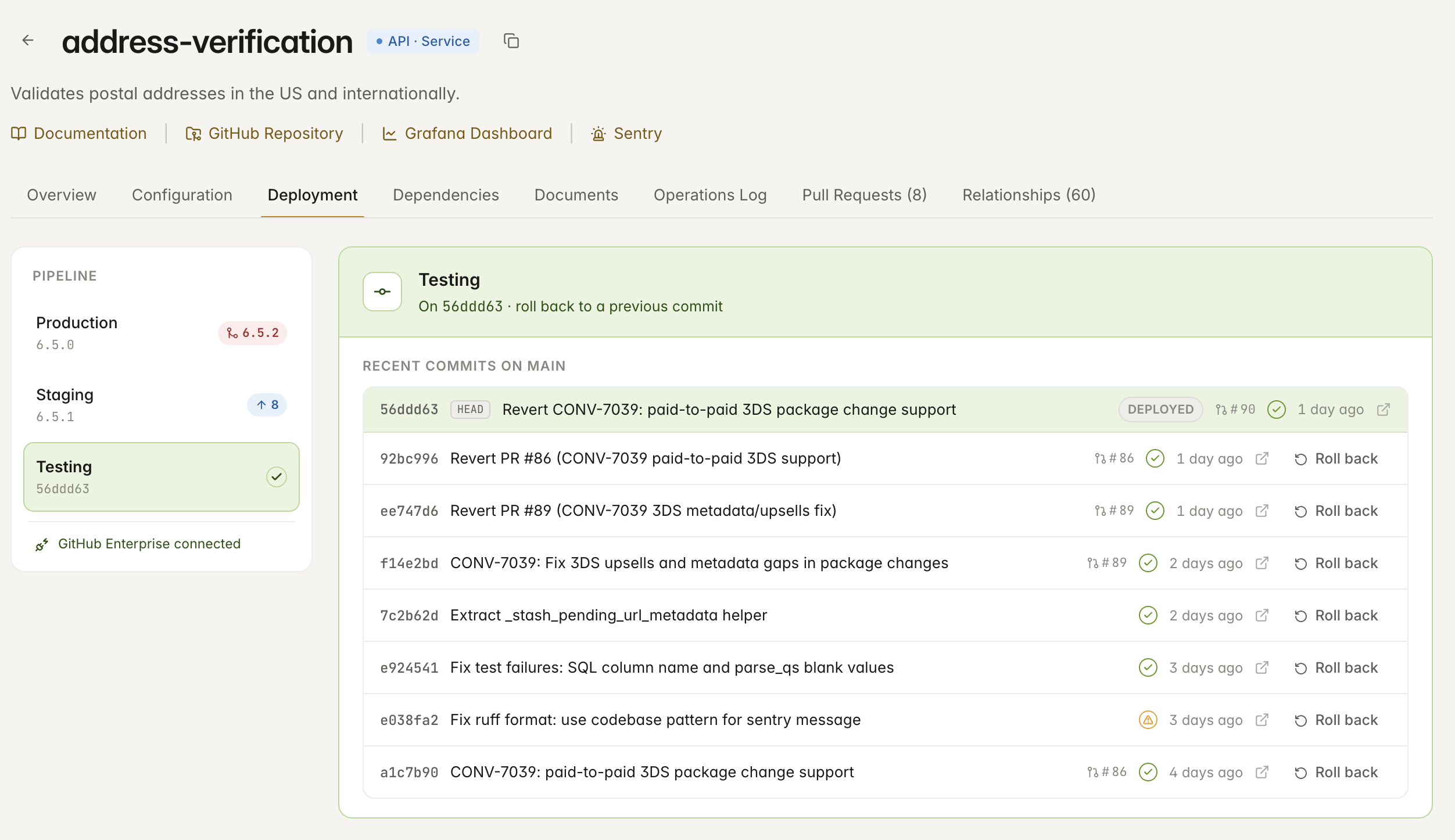
Promote a build between environments — pick the commits, and Imbi drafts the version bump and release notes from your history.
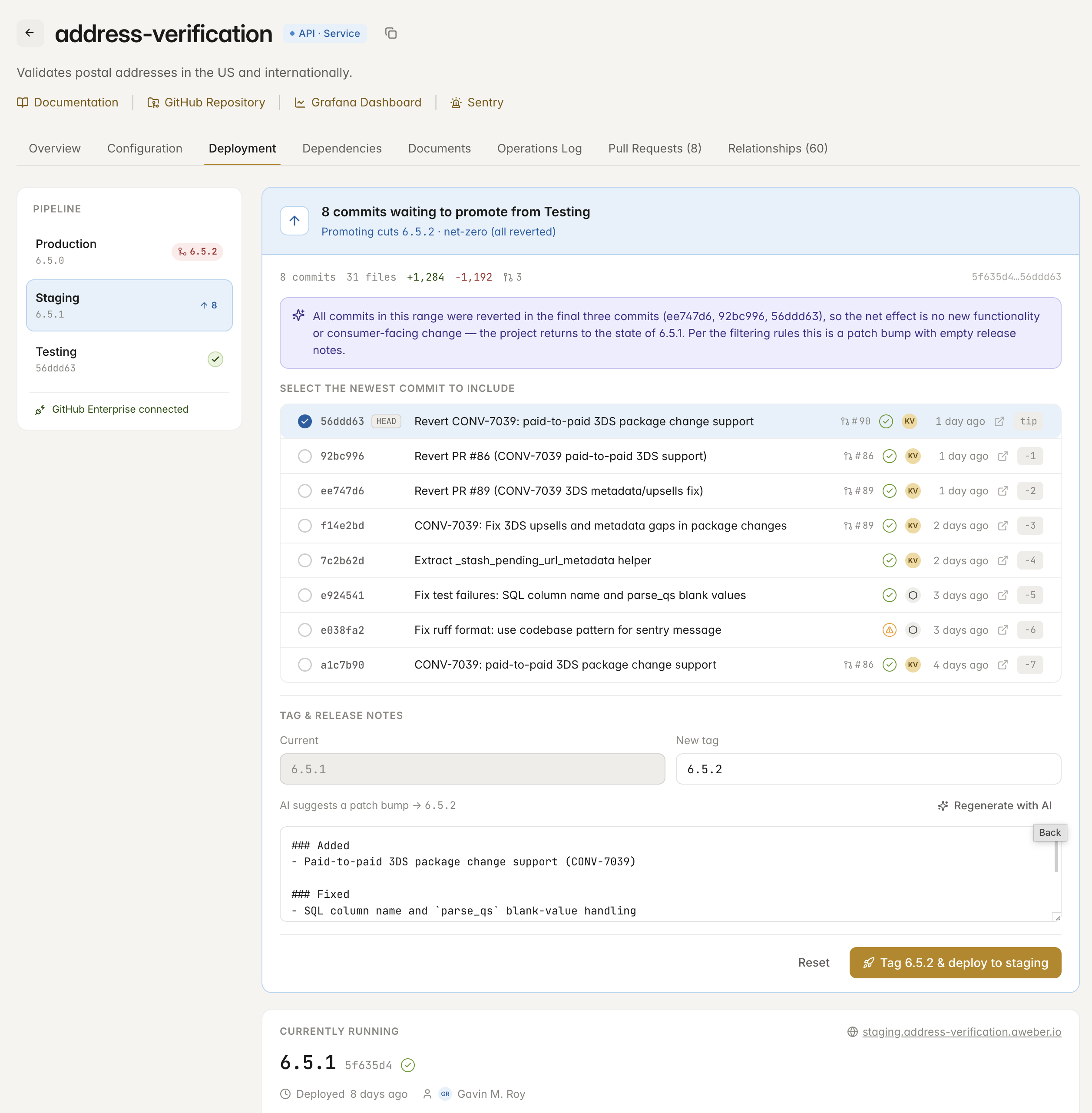
Ship a proven release to production with full notes attached — and every prior release stays one click from a rollback.
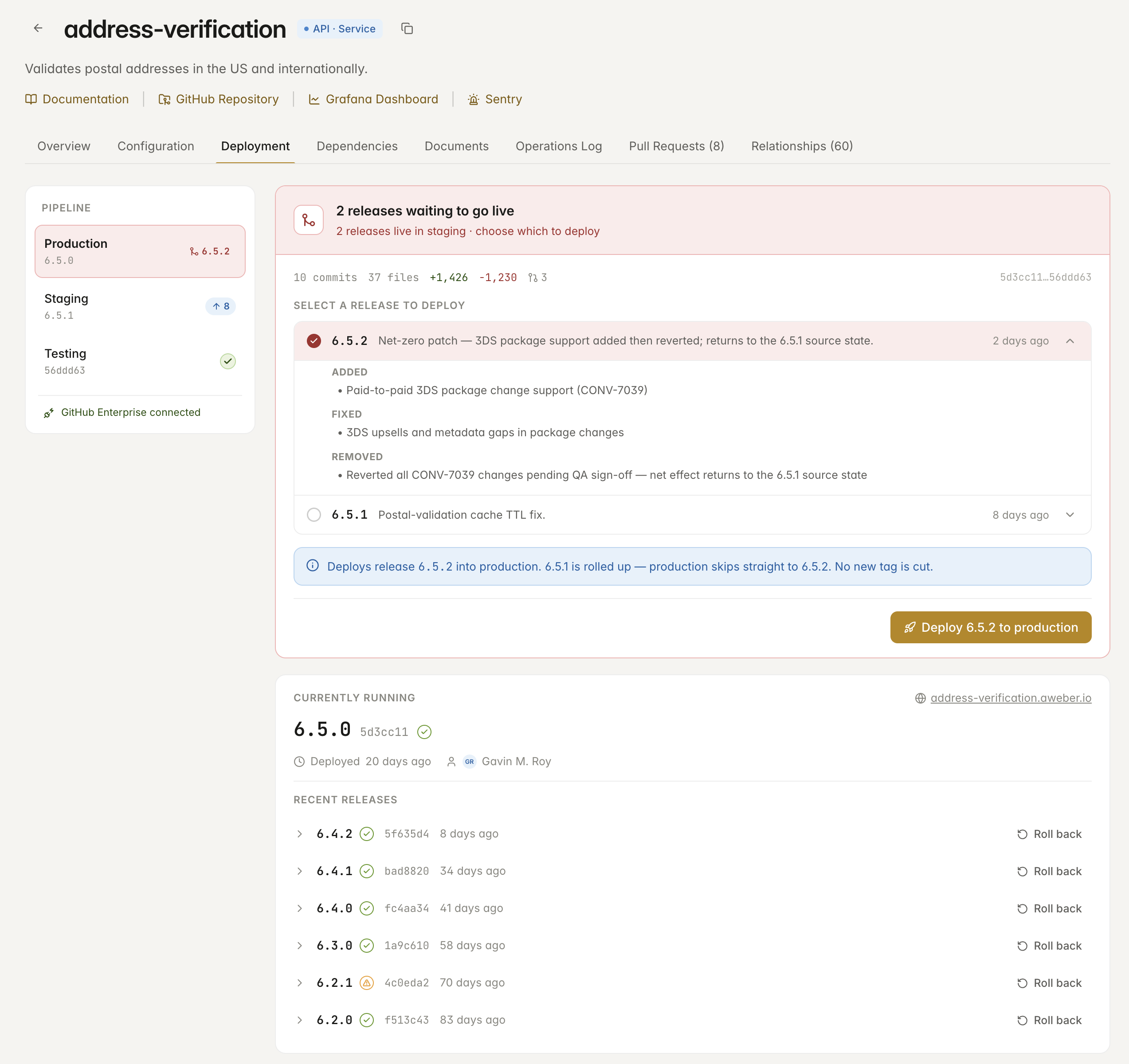
Choose which staged release goes live, or roll back to any previous version instantly.
Move a build testing → staging → production, with a clear view of exactly which commits ship at each step.
Ship a release to production, or fall back to any previous version, straight from the service's page.
Imbi reads your commit history, suggests the right version bump, and writes the release notes — even spotting when a change set nets out to nothing.
Tight integration with GitHub, GitHub Enterprise, and GitHub Enterprise Cloud — plus GitHub Actions for version bumping and deployment tracking.
Imbi's built-in assistant is backed by the live map and the latest health data — not a stale wiki. Ask who owns a service, what a change will break, or which projects are slipping, and get an answer grounded in what's true right now.
orders-api. What depends on it, who owns each piece,
and which of those are already in trouble?
orders-api, checking each one's owner, health, and on-call.Ask what an outage touches and get the full blast radius, the owning teams, and who's on call — in one answer, during the incident.
Before you change a shared service, see which teams consume it, where they're deployed, and what a breaking change would hit.
New engineers ask plain-English questions instead of hunting through ten tools. The answers reflect reality, not last year's wiki edit.
Connect the assistants your team already uses — Claude, Cursor, and others — so they answer with your org's real context, not guesses.
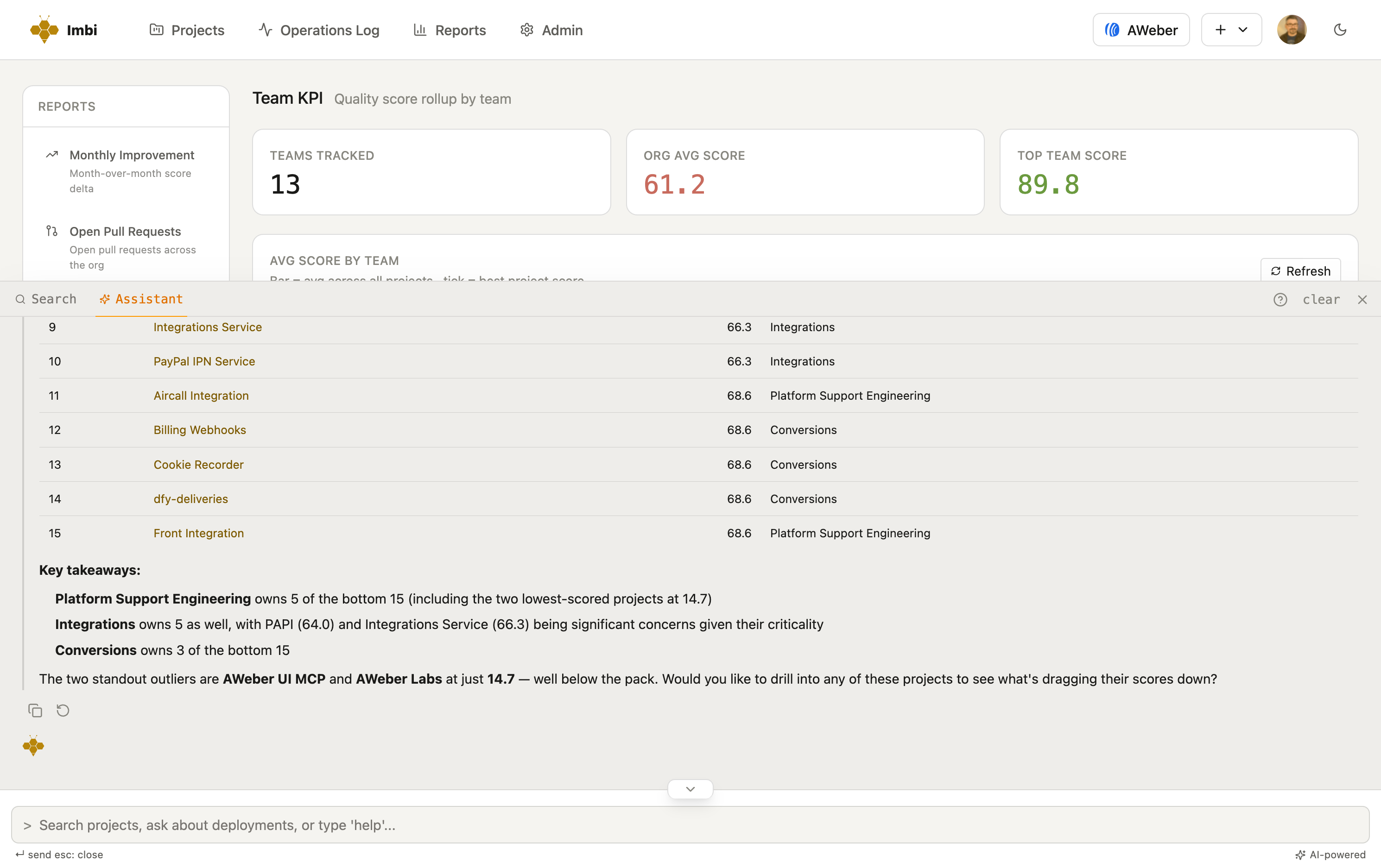
A real answer: the lowest-scoring services, who owns each, and where to look first — pulled live, not from a wiki.
Describe the change and who it applies to. Imbi runs it across every matching service, opens a pull request for each, watches the build, and even responds to review comments — so the migrations that used to take quarters fit in a workday.
services moved from GitLab to GitHub — with their pipelines converted automatically — at AWeber.
a fleet-wide Python upgrade — runtime, tooling, and standards — finished in weeks, not quarters.
instead of months, to roll a new base image across every service in the fleet.
Today you kick off automations on demand. Next, they'll respond on their own as events arrive from GitHub, your on-call tool, and your deploy pipelines — a failed deploy can trigger a rollback, a new security advisory can patch only the affected services. Plus an open plugin library, so platform teams can package reusable integrations, workflows, and playbooks for everyone else to subscribe to.
Imbi gives AI agents something they've never had: a detailed, living model of your software — the dependency graph plus the internal knowledge scattered across Confluence, Slack, and GitHub. With real context instead of guesses, an agent can pick up an event, work the problem end to end, and hand your team a reviewed pull request — not a half-formed suggestion.
payments-api, and pulled the owning team's runbook.Agents reason over the same graph and knowledge your people use, so their changes fit your system instead of fighting it.
A PagerDuty alert or a Sentry exception can wake an agent automatically — the response starts before anyone opens a laptop.
Launch, watch, and govern many agents at once from one place — the same way you manage the services they work on.
Triage, fix, pull request, and review — handled end to end, so your team can focus on the problems that actually need them.
The map, the scores, and the automations aren't separate features — they're one closed loop. What used to be a governance meeting becomes a dashboard that gets better on its own.
Deploys, incidents, quality checks — everything your tools already emit flows into Imbi without anyone copying it over.
Health recomputes per service, per team, per environment, and the full history is kept so trends are always one click away.
The services out of compliance, or matching a specific shape, are identified for you — no triage spreadsheet required.
One request runs the change across every matching service, opens the PRs, and watches them land. Scores move. The loop continues.
Imbi pulls from the tools your teams use every day and writes back what it learns. Point them at Imbi once and the catalog, the map, and the scores all keep themselves current — no data entry, no separate spreadsheet.
Imbi is BSD 3-Clause and runs great on your own infrastructure — one container, your data. A managed option is on the way for teams that want Imbi without running it. Same product, same data, either way.
Start it with one command and connect your tools. Run it on your own Kubernetes when you're ready. Your catalog, your infrastructure, your data — no vendor lock-in.
We run it. You connect GitHub, your on-call tool, and your quality checks, and get the same catalog, map, scoring, assistant, and automations — without operating anything yourself.